Guessing user drawn digit
In this post I made a fun game of drawing a number, and challenging the model to guess it correctly. The model itself is a Convolutional Neural Network (CNN) model, built using the MNIST digits datasets.
Here I want to combine it with a streamlit apps that can take live user inpu, making the inference process more interactive.
I. Streamlit code (front-end)
The full code can be found in my repo. Here’s a minimal code to highlight the main logic.
II.Model building code (back-end)
0. Imports
1. Load & explore data
1.1 Sample different ways to write each number

1.2 Check if classes are balanced
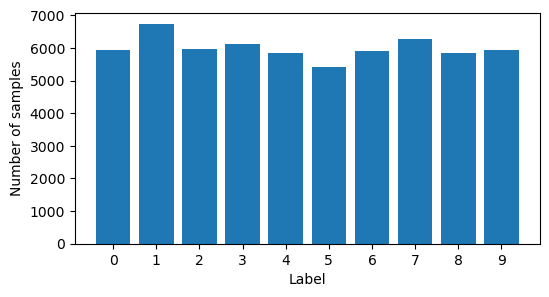
2 Transform data
3. Model
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
max_pooling2d (MaxPooling2D (None, 13, 13, 32) 0
)
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
max_pooling2d_1 (MaxPooling (None, 5, 5, 64) 0
2D)
flatten (Flatten) (None, 1600) 0
dropout (Dropout) (None, 1600) 0
dense (Dense) (None, 10) 16010
=================================================================
Total params: 34,826
Trainable params: 34,826
Non-trainable params: 0
_________________________________________________________________
Epoch 1/15
2023-02-19 22:15:15.668285: W tensorflow/core/platform/profile_utils/cpu_utils.cc:128] Failed to get CPU frequency: 0 Hz
2023-02-19 22:15:15.874289: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
422/422 [==============================] - ETA: 0s - loss: 0.3702 - accuracy: 0.8868
2023-02-19 22:15:23.874575: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
422/422 [==============================] - 9s 17ms/step - loss: 0.3702 - accuracy: 0.8868 - val_loss: 0.0942 - val_accuracy: 0.9743
Epoch 2/15
422/422 [==============================] - 6s 15ms/step - loss: 0.1146 - accuracy: 0.9653 - val_loss: 0.0643 - val_accuracy: 0.9823
Epoch 3/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0856 - accuracy: 0.9739 - val_loss: 0.0514 - val_accuracy: 0.9865
Epoch 4/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0716 - accuracy: 0.9789 - val_loss: 0.0483 - val_accuracy: 0.9872
Epoch 5/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0639 - accuracy: 0.9797 - val_loss: 0.0446 - val_accuracy: 0.9868
Epoch 6/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0573 - accuracy: 0.9829 - val_loss: 0.0391 - val_accuracy: 0.9902
Epoch 7/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0508 - accuracy: 0.9841 - val_loss: 0.0368 - val_accuracy: 0.9907
Epoch 8/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0484 - accuracy: 0.9844 - val_loss: 0.0358 - val_accuracy: 0.9890
Epoch 9/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0441 - accuracy: 0.9869 - val_loss: 0.0369 - val_accuracy: 0.9897
Epoch 10/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0413 - accuracy: 0.9871 - val_loss: 0.0344 - val_accuracy: 0.9898
Epoch 11/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0390 - accuracy: 0.9874 - val_loss: 0.0345 - val_accuracy: 0.9907
Epoch 12/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0359 - accuracy: 0.9886 - val_loss: 0.0335 - val_accuracy: 0.9905
Epoch 13/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0361 - accuracy: 0.9886 - val_loss: 0.0350 - val_accuracy: 0.9895
Epoch 14/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0323 - accuracy: 0.9889 - val_loss: 0.0314 - val_accuracy: 0.9913
Epoch 15/15
422/422 [==============================] - 6s 15ms/step - loss: 0.0320 - accuracy: 0.9895 - val_loss: 0.0299 - val_accuracy: 0.9917
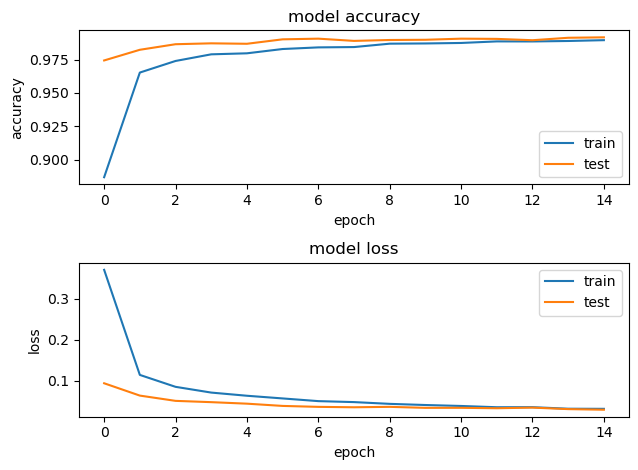
4. Evaluate performance
4.1 Predict on test data
4.2 Confusion matrix
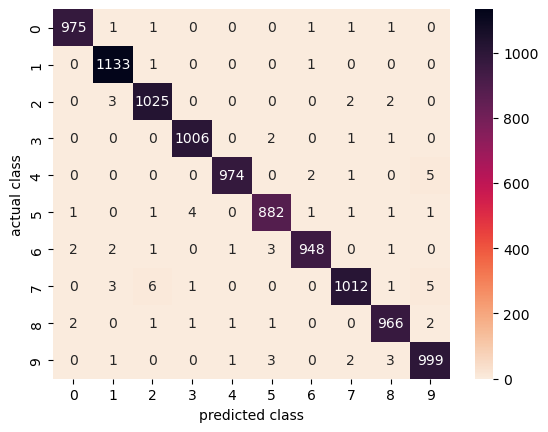
Observations:
- Majority of predictions are on the correct diagonal
- 3 and 5; 4 and 9 are commonly mistaken pairs, which is understandable because even human might make the same mistakes
5. What’s next?
- Augment data. The images in the tranining datasets are quite small (28 x 28 pixels) so I had to downsize the input image. Otherwise the drawing canvas would be very small. There are some augmentation techniques that I think will improve the model:
- Translation
- Rotation
- Scaling